Los algoritmos más usados en machine learning
Dentro del aprendizaje automático o machine learning, destacan algunos algoritmos sobre otros a la hora de resolver problemas. Estos algoritmos se repiten muy a menudo.

El machine learning o aprendizaje automático destaca dentro de la ciencia de datos debido a que estamos ante una poderosa tecnología que nos ayuda a extraer información de valor a partir de grandes volúmenes de datos para posteriormente tomar decisiones informadas.
A continuación exploraremos los algoritmos dentro de esta disciplina que han demostrado ser prácticamente indispensables a la hora de resolver problemas.
Principales algoritmos dentro de machine learning
- Redes Neuronales Artificiales:
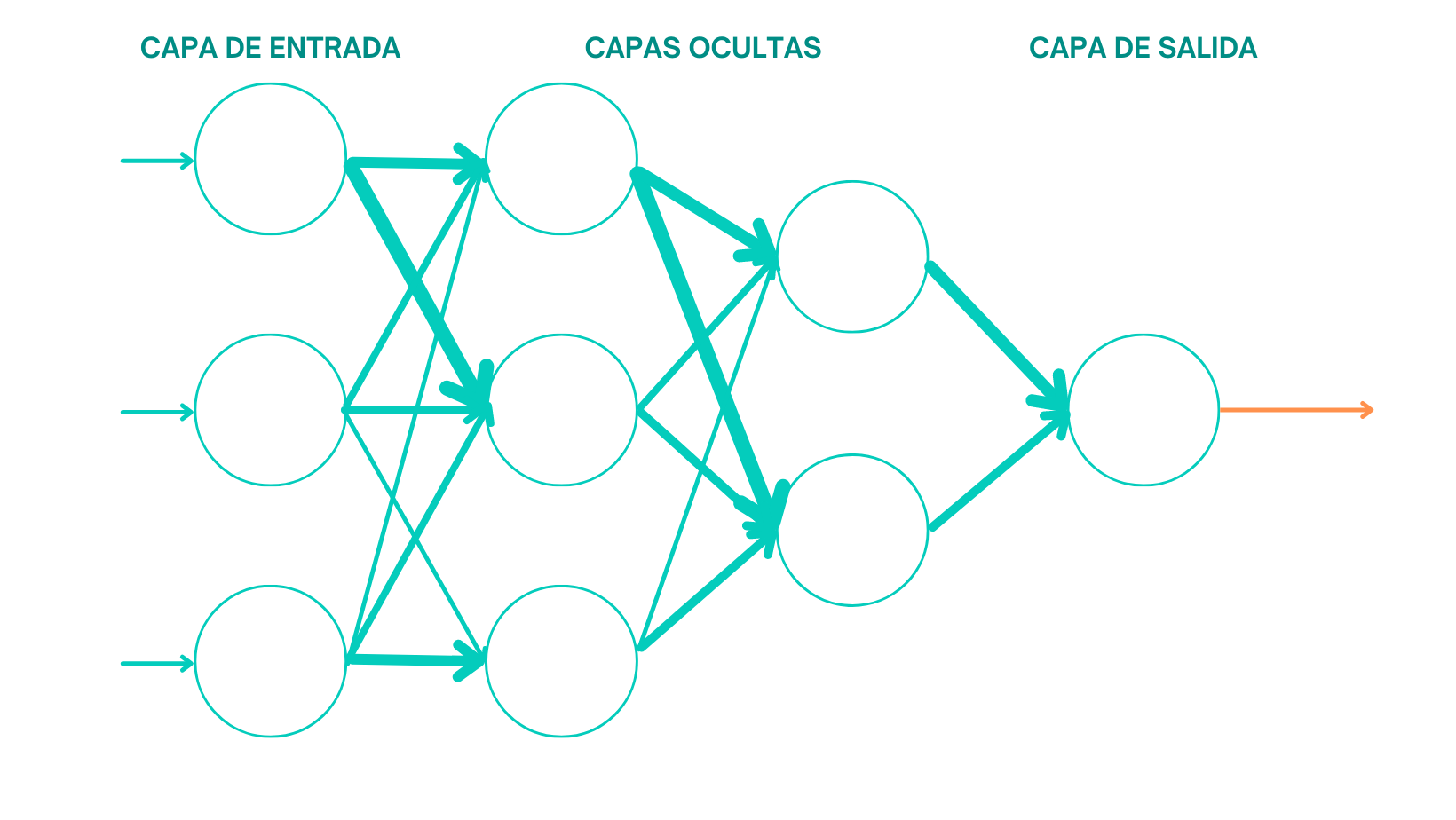
Los algoritmos de redes neuronales son un conjunto de técnicas de aprendizaje automático inspiradas en el funcionamiento del cerebro humano.
Estas redes están compuestas por unidades interconectadas llamadas neuronas artificiales, que trabajan en conjunto para procesar y analizar datos complejos.
Cada neurona toma información de sus entradas, la procesa a través de una función de activación y luego envía la salida a otras neuronas, formando así una red de conexiones.
Estas redes son utilizadas para resolver una amplia gama de problemas en ciencia de datos como el reconocimiento de patrones, clasificación, regresión, procesamiento del lenguaje natural, visión por computadora, etc.
Algunos casos de uso están en reconocimientos de imágenes, procesamiento de lenguaje natural, sistemas de recomendación, detección de fraudes y anomalías, medicina y diagnóstico, etc.
- Algoritmos de clustering:
Los algoritmos de clustering son técnicas de aprendizaje automático no supervisado que se utilizan para agrupar datos similares en conjuntos, sin necesidad de etiquetas o categorías predefinidas.
El objetivo principal de estos algoritmos es identificar patrones ocultos y estructuras dentro de los datos, agrupando elementos similares y separando aquellos que son diferentes.
A través del clustering, podemos comprender mejor la distribución de los datos y obtener información valiosa sobre la estructura subyacente de un conjunto de datos.
Estos algoritmos son ampliamente utilizados en ciencia de datos y tienen diversas aplicaciones, como por ejemplo: segmentación de clientes, análisis de mercado, segmentación de imágenes, detección de anomalías, agrupación de documentos, identificación de patrones en datos científicos, etc.
- Algoritmos de regresión:
Son técnicas de aprendizaje automático supervisado que se utilizan para predecir valores numéricos continuos basados en datos históricos previamente etiquetados.
El objetivo principal de la regresión es establecer una relación matemática entre una variable dependiente y una o más variables independientes, lo que permite realizar proyecciones y estimaciones para valores futuros.
Los algoritmos de regresión son ampliamente utilizados en ciencia de datos y tienen diversas aplicaciones, como por ejemplo: predicción de ventas y demanda, predicción del precio de bienes y servicios, análisis de tendencias climáticas, evaluación de riesgos en seguros, estimación de precios de bienes raíces, predicción del rendimiento académico, etc.

Algoritmos de árbol de decisión:
Estas son técnicas de aprendizaje automático supervisado utilizadas para la toma de decisiones basada en un conjunto de reglas lógicas y jerárquicas.
Estos algoritmos construyen un modelo en forma de árbol donde cada nodo representa una pregunta o una condición sobre los datos, y las ramas del árbol representan las diferentes posibles respuestas o resultados.
Los árboles de decisiones son utilizados para resolver problemas de clasificación y regresión, donde el objetivo es predecir una etiqueta o un valor numérico en función de características o atributos específicos.
La estructura de los árboles de decisión facilita la interpretación y explicación de los resultados, ya que las decisiones se toman de manera transparente y lógica.
Algunos casos de uso de algoritmos de árbol de decisiones son: clasificación de clientes potenciales, diagnóstico médico, evaluación crediticia, clasificación de spam, detección de fraudes, predicción de precios de viviendas, etc.
- Algoritmos bayesianos:
Los algoritmos bayesianos son técnicas de aprendizaje automático basadas en el teorema de Bayes, un concepto de probabilidad estadística desarrollado por el matemático Thomas Bayes.
Estos algoritmos se utilizan para modelar la incertidumbre y realizar inferencias basadas en datos observados y en conocimientos previos o creencias iniciales sobre un problema en particular.
Los algoritmos bayesianos son especialmente útiles cuando se tienen datos limitados o ruidosos y permiten actualizar y refinar las creencias iniciales a medida que se van recopilando más datos.
Utilizan la probabilidad condicional para calcular la probabilidad de un evento dato el conocimiento previo sobre otros eventos relacionados.
Algunos casos de uso de estos algoritmos: clasificación e correos electrónicos, filtros de contenido, diagnóstico médico, modelado de riesgo crediticio, predicción de precios de activos financieros, análisis de incertidumbre en pronósticos meteorológicos, etc.
- Algoritmos de reducción de dimensionalidad:
Los algoritmos de reducción de la dimensionalidad son técnicas utilizadas en ciencia de datos para transformar conjuntos de datos de alta dimensionalidad en espacios de menor dimensión, manteniendo al mismo tiempo la información relevante.
Estos algoritmos buscan simplificar la representación de los datos al eliminar características redundantes o ruidosas, lo que facilita su análisis, visualización y procesamiento más eficiente.
Los algoritmos de reducción de la dimensionalidad son especialmente útiles cuando se trabaja con conjuntos de datos que contienen un gran número de atributos o características, lo que puede generar problemas de sobreajuste en modelos de aprendizaje automático.
Algunas de las técnicas más comunes de reducción de la dimensionalidad son: Análisis de componentes principales (PCA), Factorización de matrices no negativas (NMF), T-Diistributed stochastic Neighbor Embedding (t-SNE), autoencoders, etc.
Conclusiones:
En conclusión, dentro de la ciencia de datos los algoritmos juegan un papel fundamental para extraer conocimientos y revelar patrones ocultos en los datos.
La combinación de estos algoritmos ha llevado a la creación de modelos cada vez más precisos y efectivos, permitiendo a los profesionales de la ciencia de datos abordar problemas de manera innovadora y generar un impacto significativo en el mundo actual.
A medida que avanza el campo de la ciencia de datos, continuaremos viendo cómo estos algoritmos evolucionan y se integran en nuevas aplicaciones y campos de estudio, proporcionando un futuro prometedor y emocionante para el análisis de datos y la toma de decisiones informadas.