Underfitting vs Overfitting
Qué es, causas, cómo detectarlo y solucionarlo

Si has llegado hasta aquí, asumimos que ya tienes ciertas nociones sobre lo que conocemos como machine learning y deep learning.
De lo contrario, te recomendamos que leas nuestros posts relacionados Deep learning y redes neuronales y ¿Qué es el machine learning y qué aplicaciones tiene?
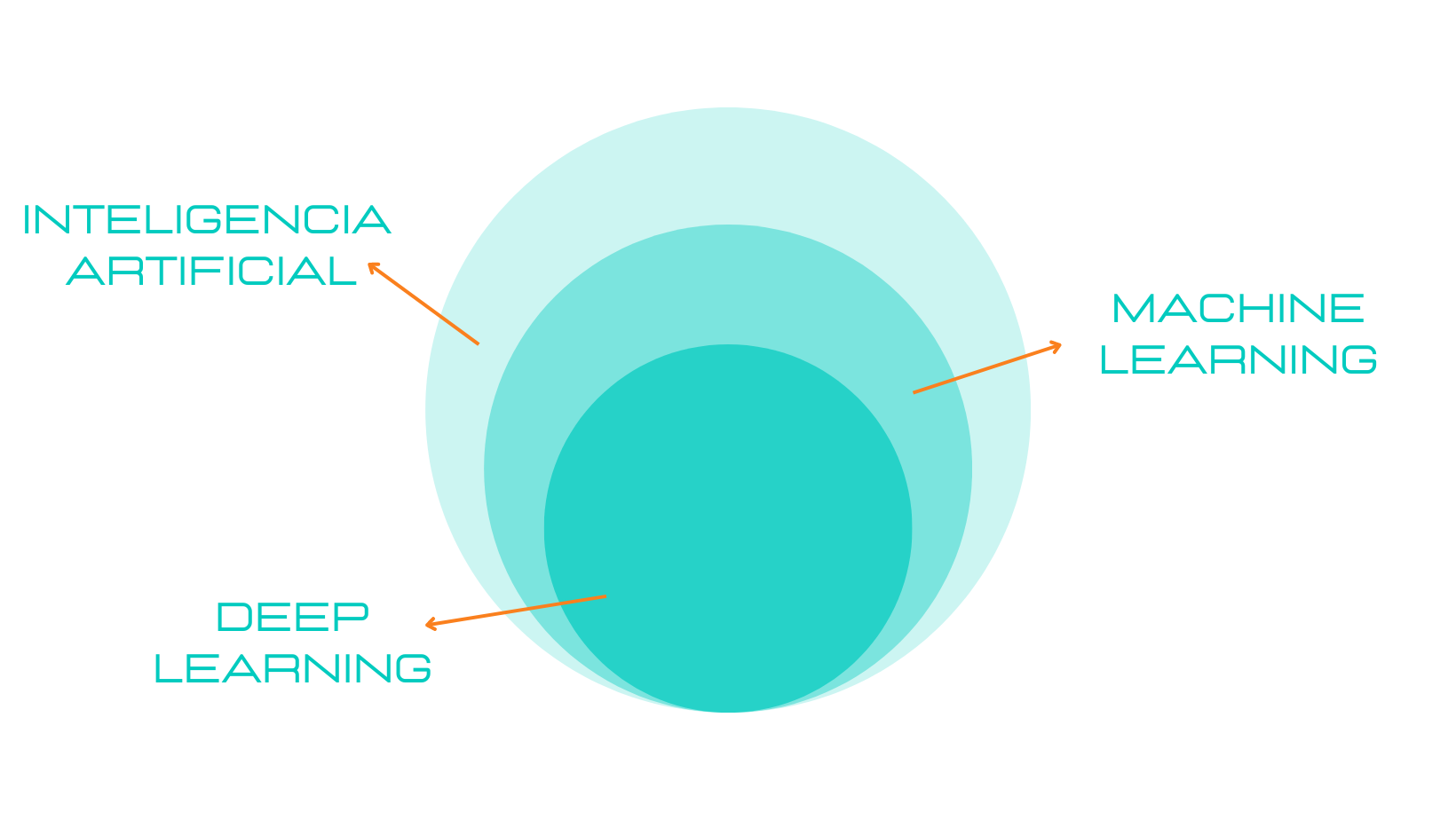
En resumidas cuentas, machine learning es una rama dentro de la inteligencia artificial la cual pretende, mediante una serie de algoritmos, brindar a nuestra computadora de la capacidad de identificar patrones en un conjunto masivo de datos y realizar predicciones.
Y dentro del machine learning tenemos a su vez, como si de una matrioshka rusa se tratase, el deep learning.ç
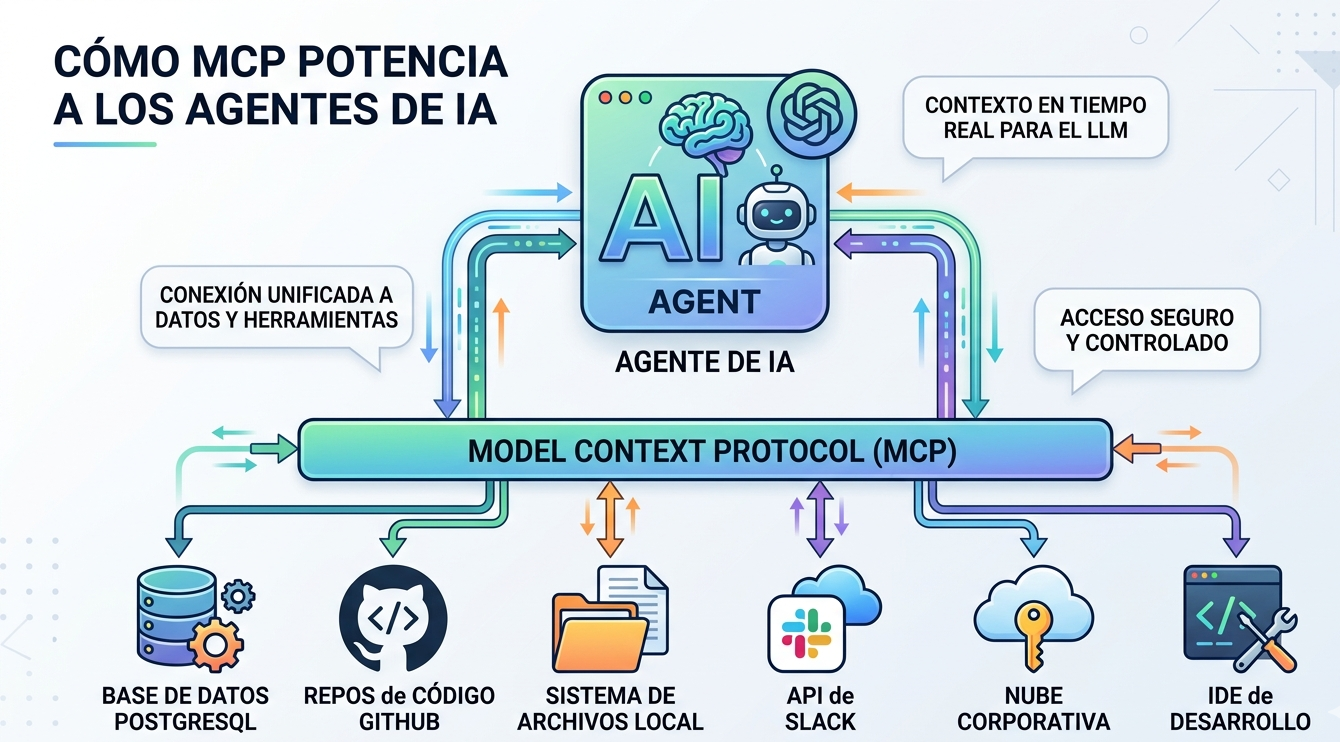
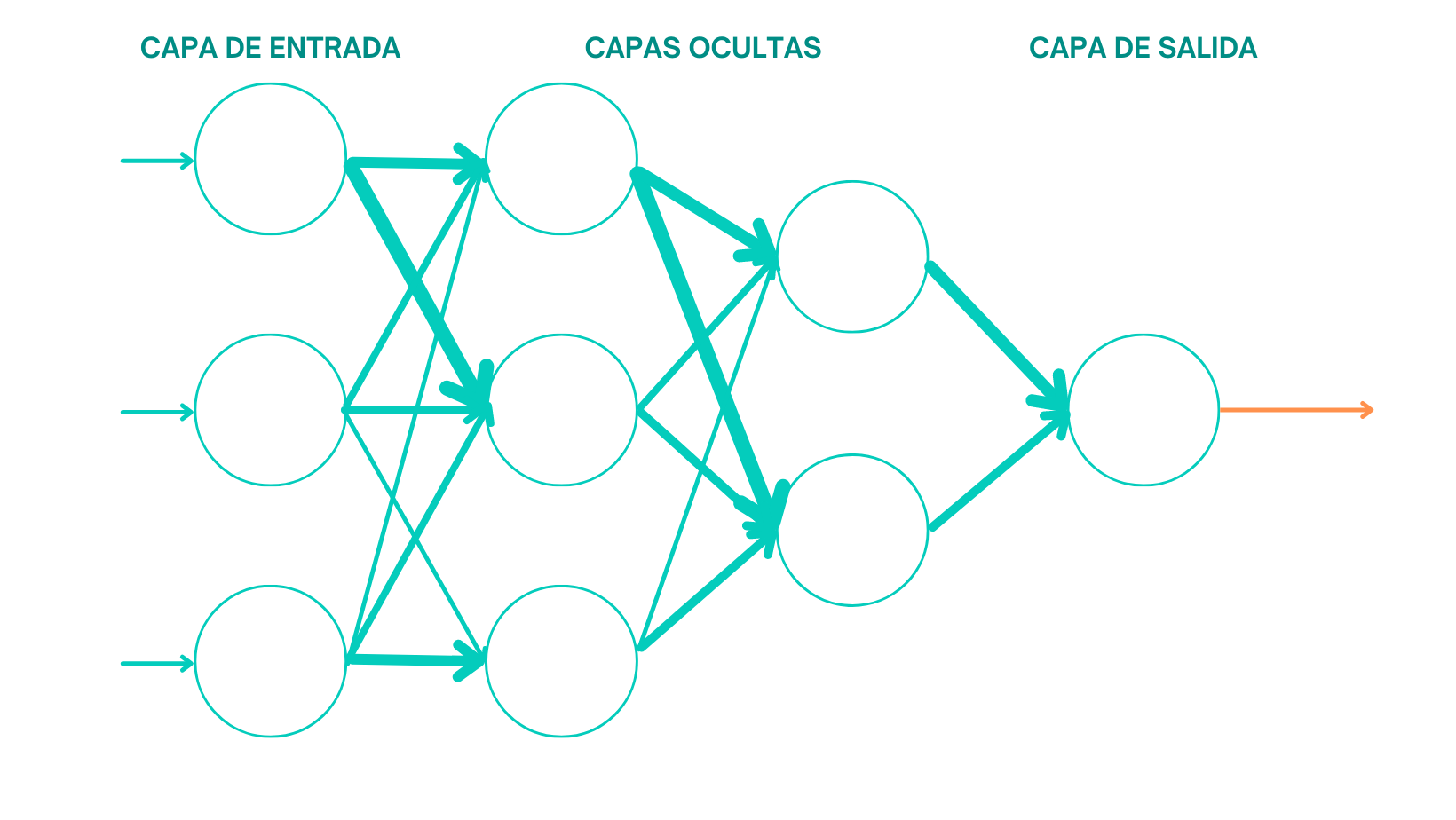
Entendamos el deep learning como un tipo de machine learning basado en redes neuronales que entrena a nuestro modelo para que realice tareas como lo haría un ser humano. Pero nosotros no queremos que nuestro modelo se limite a responder a través de una serie de ecuaciones predefinidas, ¿verdad? Nosotros queremos que nuestro modelo ¡PIENSE!, queremos que sea capaz de aprender por su cuenta y esto se logra mediante el uso de capas de procesamiento.
Pero, ¿qué ocurre cuando sobreentrenamos nuestro modelo? ¿Y si generalizamos demasiado el conocimiento que pretendemos que el modelo adquiera?
¿QUÉ ES UNDERFITTING?
La traducción al castellano sería sub-ajuste y el problema no vendría a ser otro que el anteriormente mencionado: Generalizar en exceso los inputs que introducimos en el modelo siendo poco precisos con los conocimientos que pretendemos que adquiera.
Para entenderlo fácil, supongamos que nosotros jamás hemos visto ninguna fruta. Un día, de repente, llega un amable señor y nos ofrece una naranja. Curiosos e ignorantes de nosotros, preguntamos: ¿Esto qué es? a lo que el amable señor responde: Esto es una fruta. Al día siguiente nos encontramos al mismo amable señor y nos ofrece esta vez un plátano: ¿Te apetece fruta? A lo que nosotros le respondemos confundidos: Perdona, eso no es una fruta, la fruta es naranja y redonda.
Tanto el plátano como la naranja son frutas, pero el plátano no se parece en nada a las características con que el amable señor nos describió la fruta el día anterior.
Sin embargo, supongamos ahora que ese hombre era el dueño de una frutería y al ofrecernos una pieza de fruta nos da a elegir entre: naranjas, melocotones, plátanos, kiwis, pomelos... Probablemente, la próxima vez que viéramos un tipo de fruta que desconocíamos hasta la fecha, seríamos capaces de reconocer esa nueva fruta como "fruta" al identificar características en común con el resto de frutas que ya conocíamos.
Esto es así porque como seres humanos somos capaces de conceptualizar y es lo que pretendemos que sea capaz de hacer un modelo cuando lo entrenamos. No obstante, si somos bastante genéricos o escuetos a la hora de introducir un conjunto de datos en nuestro modelo, el algoritmo no será capaz de ofrecernos un resultado bueno debido a la falta de recursos por parte del sistema para consolidar su conocimiento, abstraerse o generalizar.
A este problema se le conoce como sub-ajuste o underfitting.
Causas del underfitting:
El problema de sub-ajuste o underfitting durante el entrenamiento del modelo puede venir determinado por una o más de las siguientes causas:
- No hay suficientes parámetros para modelar adecuadamente los datos.
- El algoritmo de aprendizaje automático no ha tenido suficiente tiempo para entrenar.
- Baja entropía en el conjunto de datos de entrenamiento del modelo.

¿Cómo detectar underfitting?
Hemos mencionado anteriormente que cuando un modelo es demasiado simple con respecto a los datos que pretende modelar nos referimos a un problema de underfitting. Si nuestro modelo funciona mejor con el conjunto de datos de prueba que con el conjunto de datos de entrenamiento probablemente estemos incurriendo en underfitting.
¿Cómo solucionar el subajuste o underfitting?
Una vez sabemos que nuestro modelo sufre un sub-ajuste una de las soluciones más obvias sería ampliar el conjunto de datos de entrenamiento. De esta manera se estaría forzando al modelo a trabajar con patrones más complejos y ayudar así a reducir el underfitting. Sin embargo no siempre podemos ampliar el conjunto de datos. A veces el conjunto de datos es limitado y acceder a más de ellos no es posible. ¿Qué haríamos en estos casos?
Podríamos generar datos sintéticos, técnica conocida como Data Augmentation. Una aplicación recurrente mediante este enfoque es la manipulación de imágenes, a partir de las imágenes ya existentes en nuestro dataset podemos girarlas, recortarlas, hacerles zoom... para la obtención de nuevas imágenes.
¿QUÉ ES OVERFITTING?
Supongamos ahora el caso contrario. Imaginemos que entrenamos al modelo con frutas como puedan ser: naranjas, mandarinas, caquis, melocotones, albaricoques... y tras el entrenamiento le mostramos una sandía.
Nuestro modelo no reconocerá la sandía como fruta porque una característica inherente a los ejemplos de fruta con los que entrenó es el color "naranja". La sandía no cumple con las características que el modelo aprendió durante el entrenamiento (la condición de ser estrictamente naranja).
Así es que, cuando nos refiramos al sobre-ajuste u overfitting, de lo que estamos hablando realmente es de una deficiencia que dificulta la precisión y rendimiento del modelo.
Como concepto, esta es la esencia del overfitting. No obstante, hay una serie de conceptos estadísticos con los que te recomiendo familiarizarte si estas pensando entrenar un modelo. Para entender el sesgo existente entre los valores que introducimos y los que nos devuelve el modelo es necesario entender los siguientes términos:
- Sweet spot: el punto de equilibrio que debemos encontrar en el aprendizaje del modelo en el que nos aseguremos de no incurrir en underfitting u overfitting.
- BIAS: El BIAS o sesgo puede interpretarse como un modelo que no ha tenido en cuenta toda la información disponible en el dataset, de manera que niveles altos de BIAS indicaría un sub-ajuste o underfitting dentro del modelo. Esto ocurre cuando el modelo es demasiado simple para el problema que se quiere solucionar.
- Varianza: Indica la sensibilidad del modelo a conjuntos específicos en los datos de entrenamiento. Un algoritmo de alta varianza también aprenderá del ruido en el conjunto de entrenamiento que produce el sobreajuste.
Causas del overfitting:
A continuación dejamos algunos factores frecuentes que pueden provocar el sobre-ajuste del modelo
- Modelo demasiado potente: Cuantas más entradas se le añaden al algoritmo (por entradas nos referimos a hipótesis), el modelo se vuelve más preciso pero por contra menos consistente. Dicho de otra manera tenemos que encontrar el equilibrio entre varianza y sesgo para que exista un equilibrio también entre la precisión y la coherencia de lo que se esta midiendo. De lo contrario, podemos encontrarnos con la situación de que los modelos pueden ser radicalmente distintos si cambiamos el conjunto de datos. Ejemplo: Un modelo que permita polinomios de hasta grado 100 será más potente que uno que permita solo polinomios de hasta grado 10, no obstante, el segundo será mucho menos propenso al sobre-ajuste.
- Aprendizaje del ruido en el conjunto de entrenamiento: ocurre cuando el conjunto de entrenamiento es demasiado pequeño, el conjunto de datos tiene poca representatividad o hay demasiados ruidos (entiéndase como ruido estadístico esa variabilidad inexplicable dentro de una muestra de datos). Un algoritmo de aprendizaje automático debería ser capaz de discernir los ruidos de las variables representativas pero cuando se da alguna de las situaciones mencionadas los ruidos pueden ser tomados como valores representativos dentro de la curva de aprendizaje del algoritmo y actuar como base de predicciones.

¿Cómo detectar el overfitting?
Dentro del deep learning o aprendizaje profundo la incapacidad del modelo para generalizar conjuntos de datos es uno de los problemas más frecuentes con los que nos encontraremos. Dicha incapacidad de generalizar conjuntos de datos es una característica intrínseca de lo que denominamos sobr-ajuste del modelo y resulta prácticamente imposible detectarlo sin antes probar los datos.
Sin embargo, si hay algo que podamos hacer para concluir la presencia de overfitting.
Dividimos el conjunto principal de datos en dos subconjuntos: Conjunto de datos de entrenamiento (80% aprox. del conjunto principal) y conjunto de datos de prueba (20% aprox del conjunto principal).
El conjunto de entrenamiento contiene la mayoría de datos disponible y es con el que entrenamos el modelo mientras que el conjunto de prueba tiene una representación mucho menor y se utiliza para probar la precisión del modelo con datos con los que no actuó anteriormente.
Mediante la segmentación de los datos en subconjuntos podemos medir la precisión del modelo en cada conjunto para determinar la existencia de sobre-ajuste. Si el modelo funciona claramente mejor con el conjunto de entrenamiento que en el conjunto de prueba, probablemente nos encontremos ante un caso de overfitting.
¿Cómo solucionar el overfitting o sobreajuste del modelo?
Veamos algunas de las técnicas más frecuentes para lidiar con el sobre-ajuste de un modelo.
- Simplificación del modelo: La manera de lograrlo dependera del método de machine learning utilizado. En caso de trabajar con redes neuronales habríamos de disminuir el numero de capas o neuronas. Podemos lograr este objetivo mediante el uso de técnicas como el Dropout que consistiría en la eliminación de neuronas de la red neuronal basándonos en la probabilidad dada por la distribución de Bernoulli; o bien mediante Early Stopping. La técnica Early Stopping o Parada Temprana consiste en evaluar el modelo durante el entrenamiento tanto en el conjunto de entrenamiento como en el conjunto de prueba. Al principio lo lógico y más probable es que el modelo mejore rendimientos en ambos conjuntos sin embargo, llegará un punto en el que el modelo mejore en el conjunto de entrenamiento pero comience a empeorar en el conjunto de prueba. Utilizando este método de regularización de modelos lineales, este es el punto que denominamos de Parada Temprana para evitar el sobre-ajuste.
- Data Augmentation: Generación de nuevos datos a partir de los ya existentes. Aplicable normalmente a imágenes como vimos anteriormente.
- Eliminación del ruido del conjunto de entrenamiento: Cuando recibimos los datos antes de entrenar al modelo debemos realizar lo que se conoce como Data Cleaning y no es otra cosa que depurar el modelo limpiándolo de impurezas eliminando outliers, estandarizando los datos y eliminando toda información irrelevante que pueda añadir ruido a nuestro modelo. Una mala limpieza de datos del modelo antes de ponernos a trabajar con él puede generar overfitting.
- Conseguir más datos: No siempre es fácil o posible, pero siempre que se pueda aumentar el numero de observaciones puede ayudar a solucionar el problema y si no es el caso, habrá que recurrir a alguna de las otras metodologías mencionadas.
- Transfer Learning: Puede darse el caso en el que no sea posible conseguir más datos ni generarlos y que el sobre-ajuste venga determinado por la escasez de datos a nuestra disposición. En estos casos se puede coger un modelo ya entrenado y funcional, que tenga una función similar al que estamos intentando entrenar y reentrenarlo con el conjunto de datos de entrenamiento actual.
Y hasta aquí todos los conceptos y diferencias clave entre el overfitting y underfitting.