¿Cómo funciona el algoritmo y el sistema de recomendación de Spotify?
En este artículo podrás encontrar desglosado el funcionamiento del sistema de recomendación de Spotify basado en el uso del deep learning.

Spotify es una plataforma que hoy en día prácticamente cualquier persona conoce, ya que tiene más de 400 millones de usuarios mensuales.
Esta aplicación es un servicio de música, podcasts, etc. donde puedes escuchar muchísimas canciones y contenido de creadores de prácticamente cualquier parte del mundo.
Permite escuchar música de forma totalmente gratuita, indistintamente de si posees la versión gratuita o premium. Además, podrás crear tus propias listas y colecciones, incluye recomendaciones basadas en tus gustos, etc.
Es sobre esta última de la que vamos a hablarte.
Y es que, al igual que con Netflix, una de las grandes ventajas que posee Spotify frente a su competencia, es su sistema de recomendación basado en tus gustos.
Este sistema está formado a partir del uso de deep learning, ofreciendo a los usuarios una experiencia de uso totalmente personalizada basada en los datos que la propia plataforma ha ido recopilando.
Pero... ¿Qué es el deep learning?
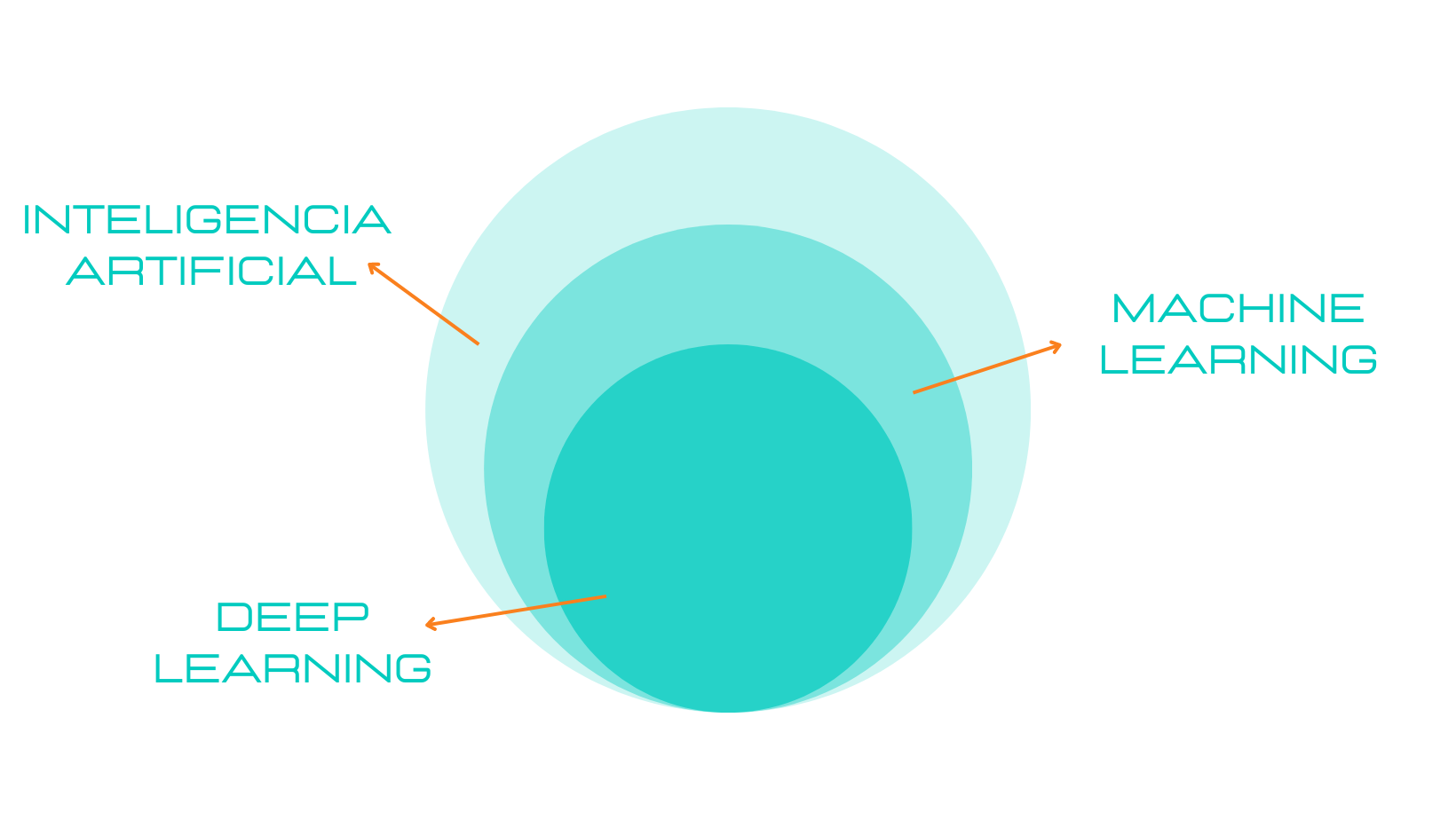
Antes de nada, conocer el contexto dentro del que se encuentra el deep learning es fundamental para poder entender mejor el sistema de recomendación que utiliza Spotify.
Para ello, vamos a explicar brevemente el significado de inteligencia artificial, machine learning y deep learning.
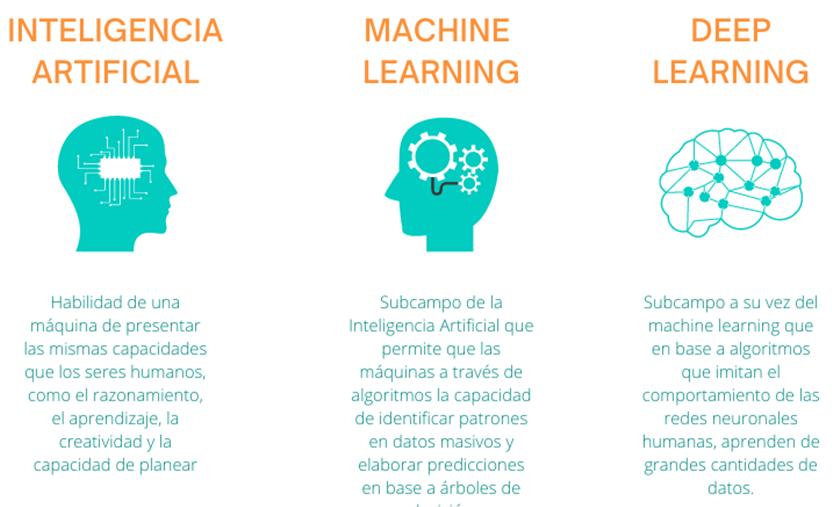
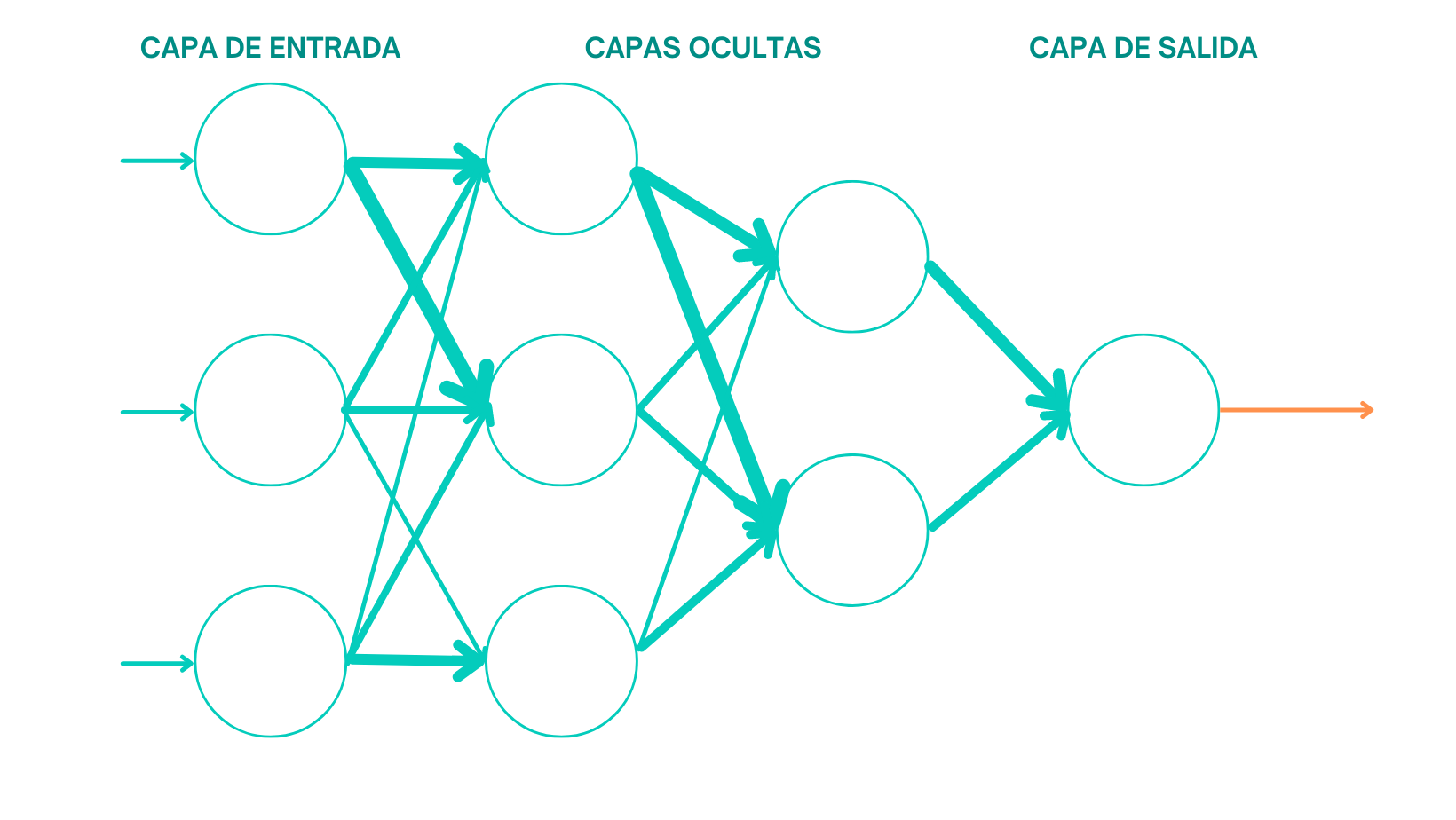
En otras palabras, el deep learning está formado por algoritmos que se inspiran en cómo funcionan y se comportan las redes neuronales humanas formando redes neuronales artificiales, esto permite que el algoritmo "aprenda" con el mismo razonamiento que un humano.
Actualmente el deep learning se encuentra acaparando la mayoría de las investigaciones ya que son algoritmos muy potentes con infinidades de usos.
Si deseas conocer más sobre el deep learning y el funcionamiento de las redes neuronales artificiales, visita ese artículo.
Una vez que nos encontramos en contexto, vamos a desglosar a continuación los 3 sistemas de recomendación que utiliza la plataforma para poder recomendar a los usuarios música similar a la que escuchan o tienen marcada como favorita.
No hay que dejar a un lado que esta técnica se utiliza principalmente para mejorar la experiencia del usuario mientras este se encuentra dentro de la aplicación y por ende, aumentar el tiempo de uso de la misma.
Modelos de recomendación utilizados por el algoritmo de Spotify

Como hemos mencionado anteriormente, Spotify tiene 3 mecanismos para hacer recomendaciones dentro de su plataforma.
1. MODELO DE FILTRADO COLABORATIVO.
Puede que te suene este modelo ya que es el que utiliza Netflix para hacer sus recomendaciones de películas. Fue la primera compañía en implementarlo y debido a su gran éxito, muchas comenzaron a aplicarlo.
Este modelo analiza el comportamiento de los distintos usuarios con las canciones, podcast, listas de reproducción, etc. De esta forma, le muestra al usuario canciones que pueden gustarle porque usuarios con gustos similares a él las escuchan.
Para que se entienda mejor vamos a poner un ejemplo:
- El usuario 1 escucha las canciones A, B y C
- El usuario 2 escucha las canciones A, B y D
- Entonces, Spotify detecta que son usuarios con gustos similares y por lo tanto, les gustarán las mismas canciones. Al usuario 1 le recomienda escuchar la canción D y al usuario 2 le recomienda escuchar la canción C.
Pero, ¿Cómo funciona este sistema de filtrado colaborativo?
Este modelo trabaja con la matriz de interacciones. La tarea del aprendizaje automático es aprender una función que prediga que canciones le van a gustar a cada usuario. La matriz suele ser enorme, muy dispersa y la mayoría de los valores faltan.
Cada fila de matriz representa uno de los más de 400 millones de usuarios de Spotify y cada columna representa una de las más de 35 millones de canciones de la plataforma.
Después, la biblioteca de Python ejecuta una fórmula de factorización de matriz larga y complicada que da como resultado, dos tipos de vectores (representados por X e Y). X es el vector usuario que representa el gusto de un solo usuario, e Y es el vector canción que representa el perfil de una sola canción.
En este punto, tenemos más de 400 millones de vectores de usuario y más de 35 millones de vectores de canción. Por sí solos, no aportan ninguna información, pero cuando los comparamos obtenemos una información muy valiosa.
Para conocer qué usuarios tienen unos gustos similares a los nuestros, hay que comparar nuestro vector con el resto de vectores, de esto se encarga el filtrado colaborativo. Una vez hecho esto, conoceremos qué usuarios son los más cercanos a nosotros. Y lo mismo ocurre con las canciones, cuando comparamos el vector de una canción con el resto de vectores de canción, encontramos qué canciones son similares.

2. MODELO DE PROCESAMIENTO DE LENGUAJE NATURAL.
Otra forma que utiliza Spotify para hacer recomendaciones a sus usuarios es a través del procesamiento del lenguaje natural.
Las canciones al tratarse de audios no cuentan con palabras escritas que describan la canción, es decir, no se puede procesar ningún texto que nos diga si la canción es veraniega, nostálgica, divertida...
Para ello, se utilizan todos los contenidos publicados en la red como pueden ser blogs, sitios webs, artículos de revistas digitales, etc. en los que se hable de la canción o artista que se está estudiando para descubrir qué adjetivos o palabras se usan más frecuentemente para describir esa canción o artista en concreto.
Una vez que se han analizado todos estos contenidos, el algoritmo crea una matriz informativa que sirve como base de datos y podemos buscar similitudes entre canciones. Además, a cada término que define el track musical se le da una ponderación para saber la relevancia que tiene cada palabra en cada canción.
Por otro lado, también se busca en los artículos, blogs, etc. los artistas y canciones que se mencionan junto a otros.
3. MODELO DE AUDIO SIN PROCESAR.
En este modelo, se analizan las canciones en sí para conocer sus características (duración de la canción, volumen, tempo, clave, etc.) y de esta forma trazar similitudes entre unas y otras.
Es muy útil sobre todo para poder recomendar aquellas canciones que son nuevas y aún no tienen ningún tipo de historial porque se puede comparar las características de esta canción con las de otras para encontrar similitudes y mostrársela a los usuarios que escuchan esas canciones similares.
¿Y cómo se analizan las canciones para obtener sus características?
La respuesta es muy sencilla, con redes neuronales convolucionales. Es la misma tecnología que se utiliza en el software de reconocimiento facial, pero en el caso de Spotify se ha modificado para usarlo en audios en lugar de píxeles.
CONCLUSIÓN
Gracias a estos tres modelos de recomendación, Spotify es capaz de hacer millones de recomendaciones basada en diferentes criterios ofreciendo una experiencia única.
Otorga a los usuarios la oportunidad de escuchar música nueva cada día sin repetir ninguna canción y descubrir nuevos artistas.
Cada día podemos ver la importancia que tienen la Inteligencia Artificial, el Machine Learning y el Deep Learning en los negocios.
Trabajar los datos y utilizarlos a nuestro favor puede suponer una gran diferencia en nuestra empresa.